Xubo Liu 刘徐博
|
I am a Research Scientist and the Speech Team Leader at Stability AI, London, UK. My Ph.D. supervisors are Prof. Wenwu Wang and Prof. Mark D. Plumbley at University of Surrey. My passion is to build AI models to understand the world with multi-modalities and engage with humans. Currently, I work on computational auditory scene analysis, multimodal content creation and large language models for audo/speech/music signals. Previously, I interned with Dr. Christian Fuegen and Dr. Egor Lakomkin at Meta AI, London. During my PhD, I worked closely with Dr. Qiuqiang Kong at the Chinese University of Hong Kong (CUHK). I graduated with First Class Honors from Queen Mary University of London in 2020 with a BSc in Telecommunications Engineering. I am open to research collaborations. Please feel free to email me.
Email:
xubo.liu@surrey.ac.uk
Personal: [Google Scholar] | [Github] | [Linkedin] | [Twitter] |

|
|
|
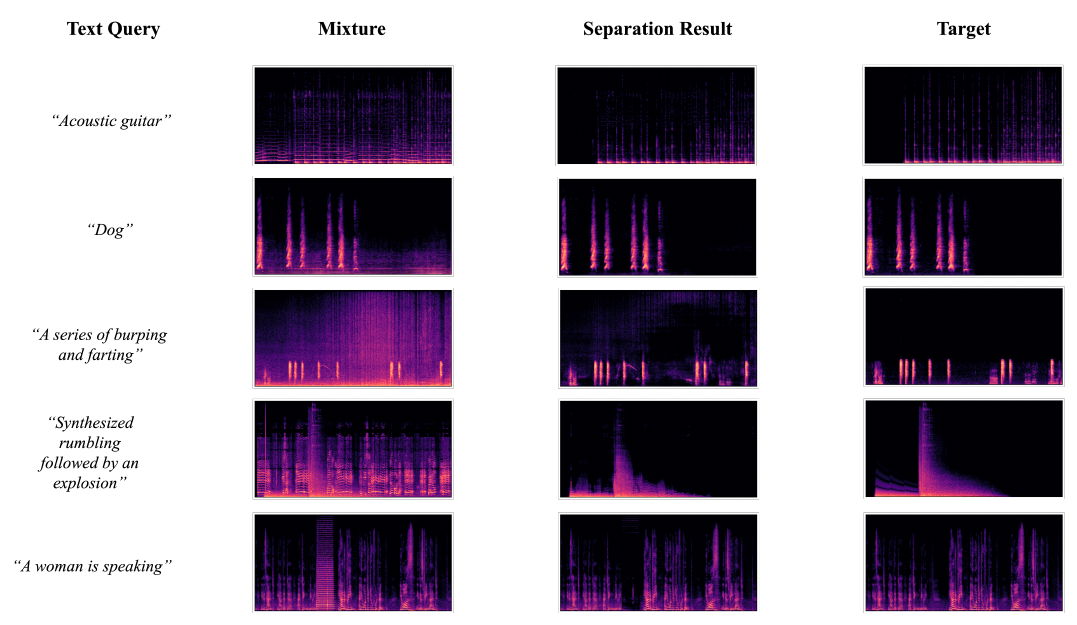 |
Xubo Liu, Qiuqiang Kong, Yan Zhao, Haohe Liu, Yi Yuan, Yuzhuo Liu, Rui Xia, Yuxuan Wang, Mark D Plumbley, Wenwu Wang Transactions on Audio, Speech and Language Processing (TASLP) paper | project | code 
Media coverage: |
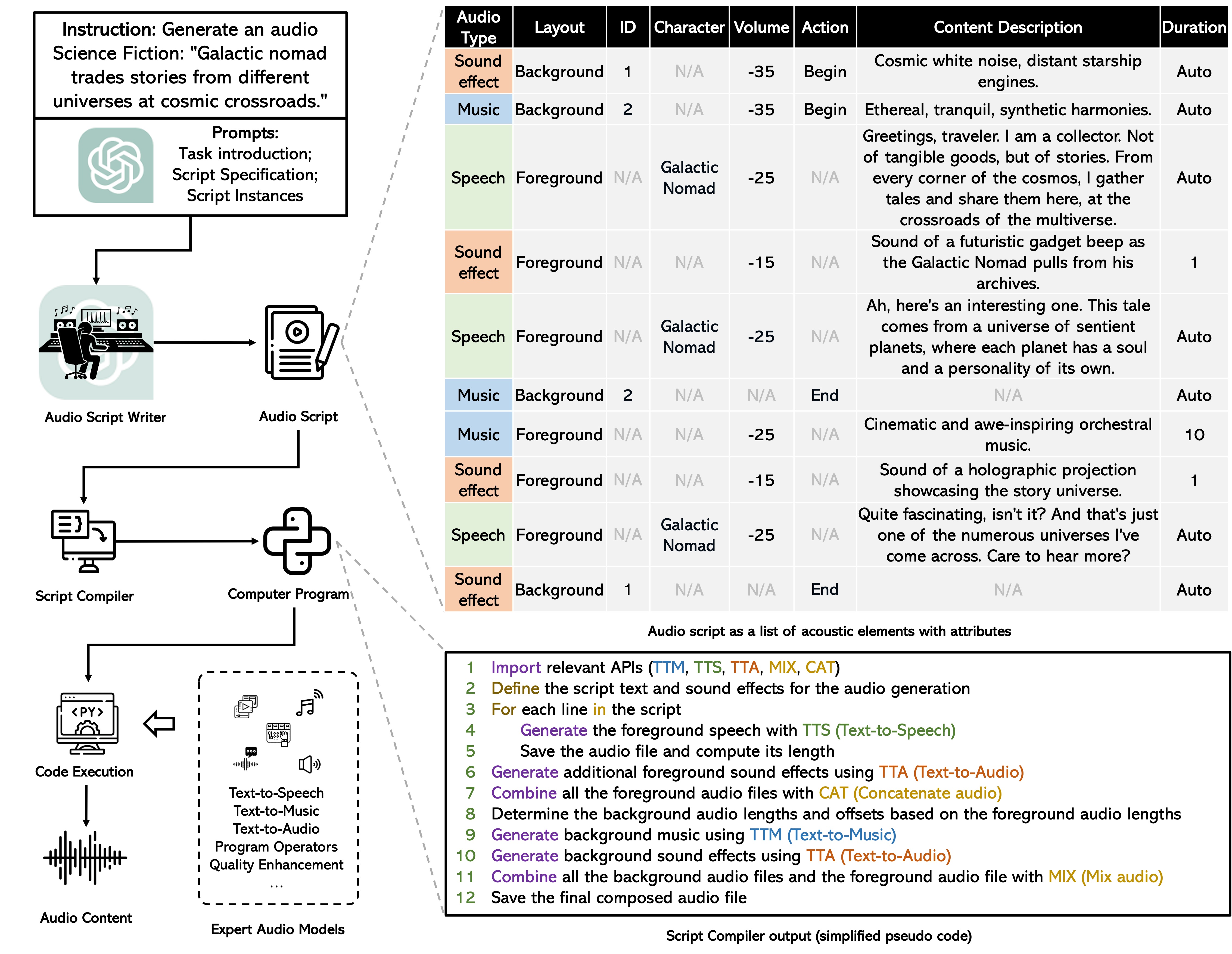 |
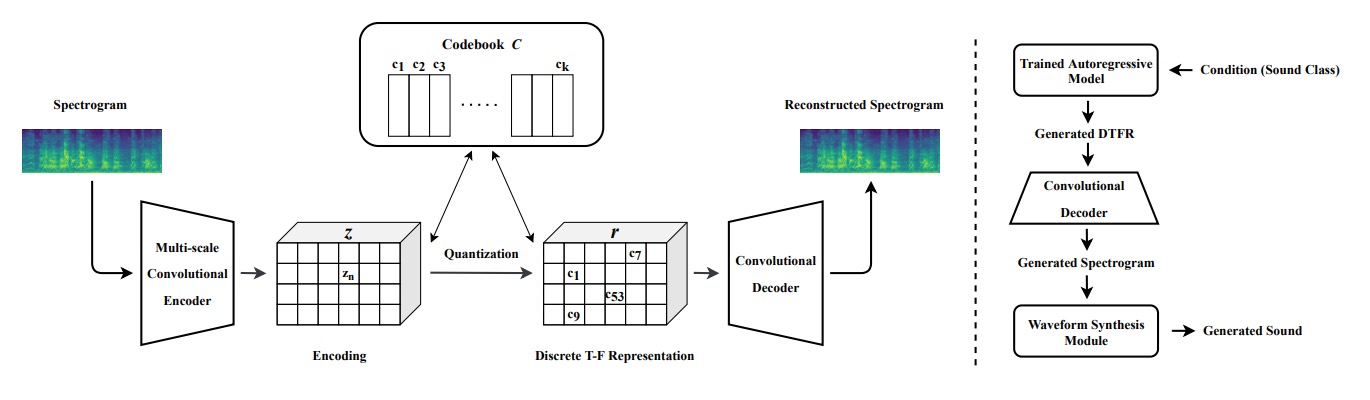
Xubo Liu, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, Yin Cao, Qiuqiang Kong, Mark D Plumbley, Wenwu Wang arXiv:2307.14335 paper | project | code 
Media coverage: |
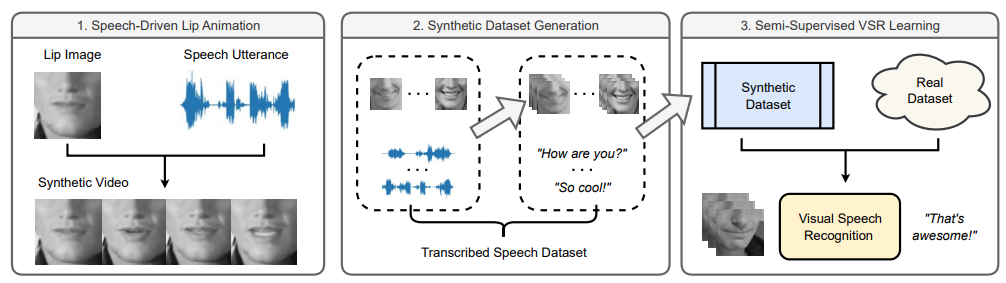 |
Xubo Liu, Egor Lakomkin, Konstantinos Vougioukas, Pingchuan Ma, Honglie Chen, Ruiming Xie, Morrie Doulaty, Niko Moritz, Jachym Kolar, Stavros Petridis, Maja Pantic, Christian Fuegen CVPR 2023 paper | project |
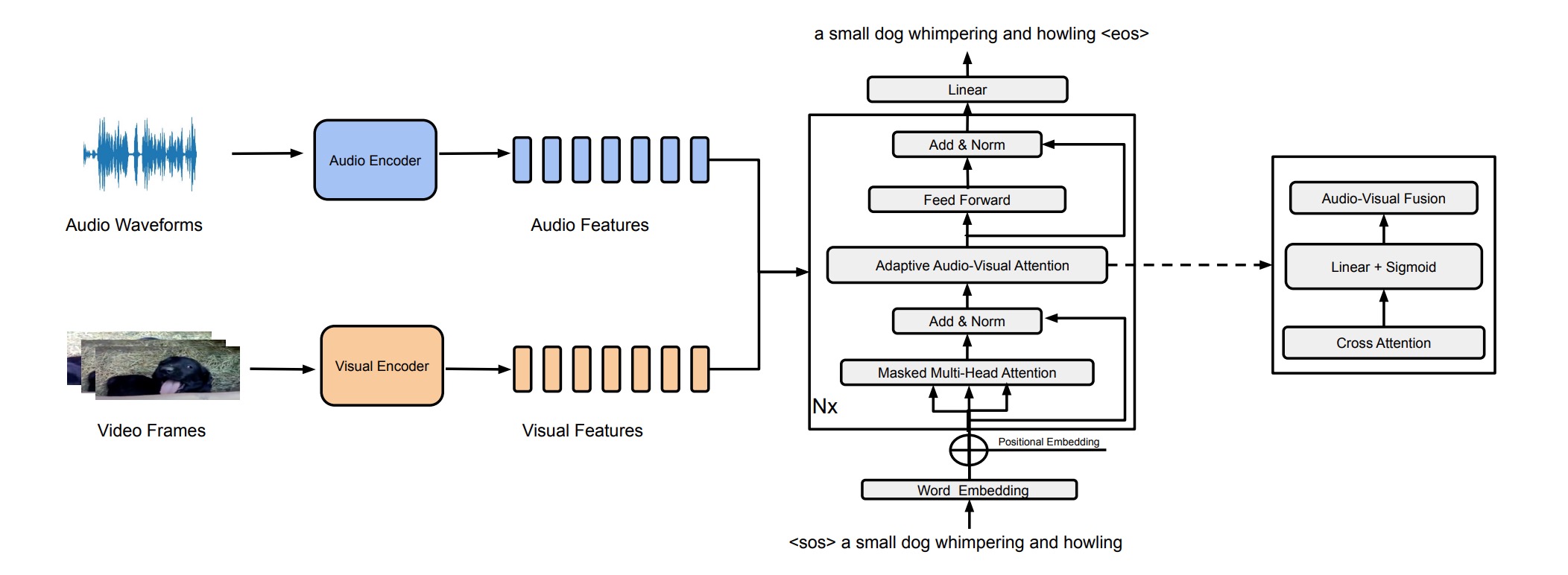 |
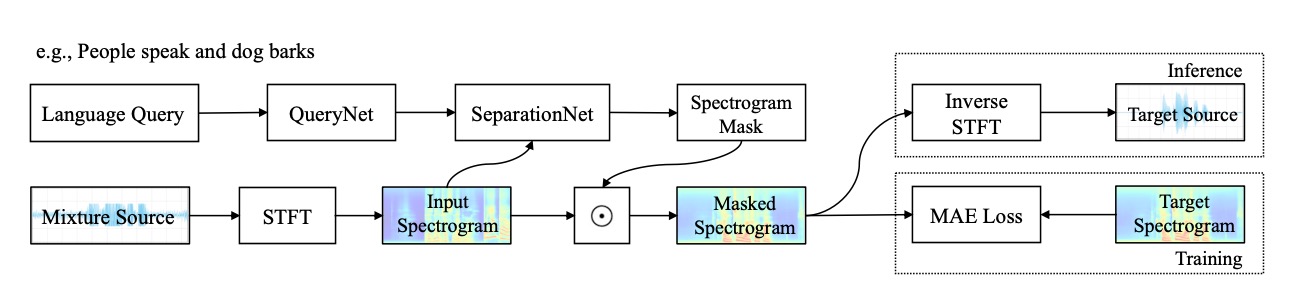
Xubo Liu, Qiushi Huang, Xinhao Mei, Haohe Liu, Qiuqiang Kong, Jianyuan Sun, Shengchen Li, Tom Ko, Yu Zhang, Lilian H Tang, Mark D Plumbley, Volkan Kılıç, Wenwu Wang Interspeech 2023 paper | code 
|
 |
Xubo Liu, Haohe Liu, Qiuqiang Kong, Xinhao Mei, Mark D. Plumbley, Wenwu Wang ICASSP 2023 paper | code 
|
 |
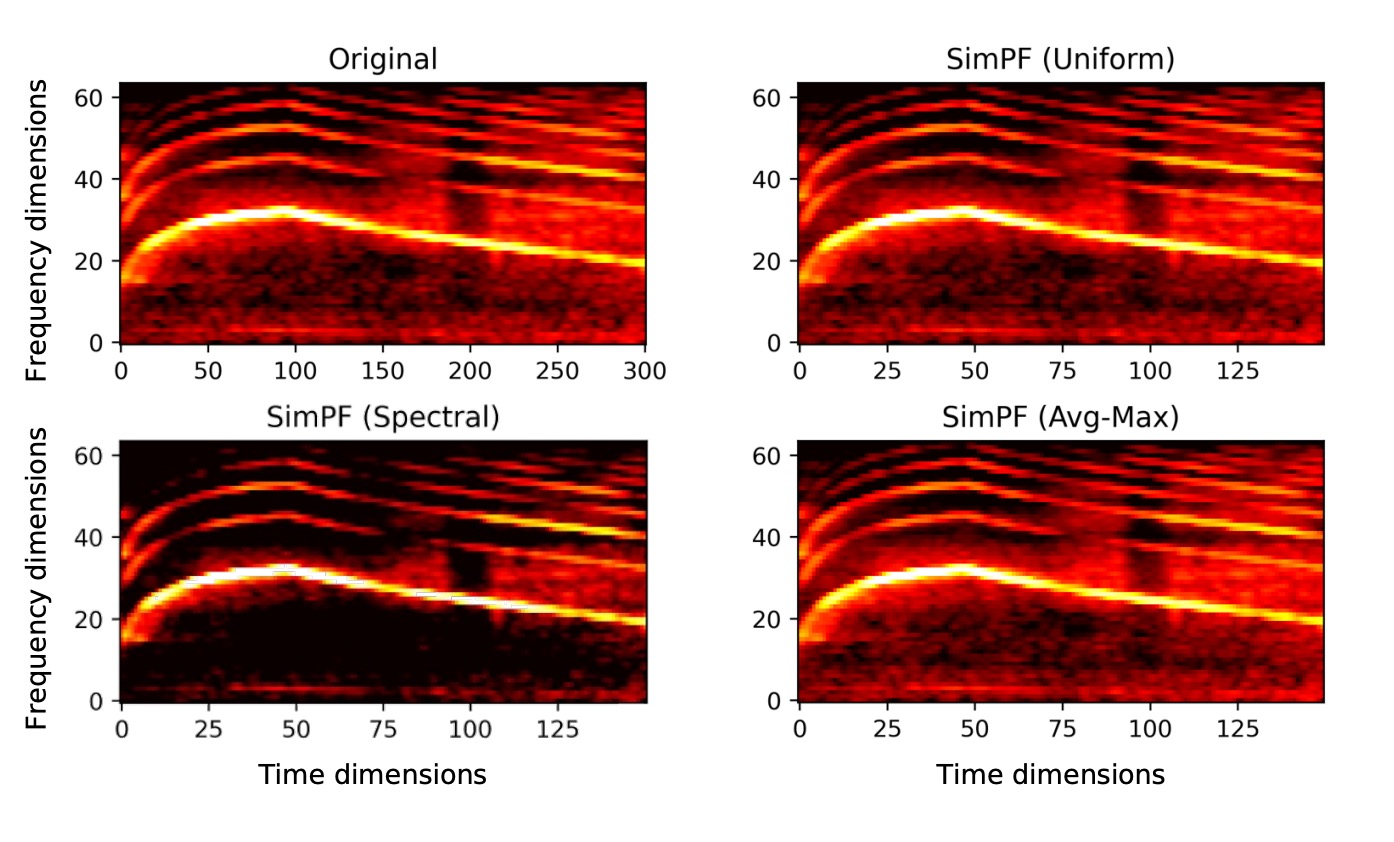
Xubo Liu, Haohe Liu, Qiuqiang Kong, Xinhao Mei, Jinzheng Zhao, Qiushi Huang, Mark D Plumbley, Wenwu Wang Interspeech 2022 paper | project | code 
|
 |
Xubo Liu, Turab Iqbal, Jinzheng Zhao, Qiushi Huang, Mark D Plumbley, Wenwu Wang MLSP 2021 paper | code 
|
|
Special Session Chair of Multimodal Learning for Audio and Language" at EUSIPCO 2023 Journal reviewer: IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), IEEE Signal Processing Letters, International Journal of Computer Vision (IJCV) Conference reviewer: ECCV (24), ICML (24), CVPR (24), EMNLP (23), ICASSP (23-24), INTERSPEECH (22-24), MLSP (23) |
Template credits: Unnat |